AutoML and the Future of Data Science

If you’re reading this, you likely already know what AutoML, or Automated Machine Learning, is. It’s a tool built by Google to automate the full machine learning pipeline, and Microsoft and Amazon have their own implementations in the cloud as well.
Automated Machine Learning is built to conduct a broad and deep search over a vast landscape of models and hyperparameters to find the best model and feature engineering for the problem. In addition to automating a large part of current Machine Learning projects, it’s also relatively easy to get started. Depending on the technical infrastructure at your organization, it can be quite simple for those with software or cloud experience to run their own models at scale.
Due to this and a plethora of low-code/no-code tools taking the industry by storm, we see plenty of articles claiming that AutoML will replace Data Scientists. I disagree, to an extent, and in this story, I’ll unravel what I believe will happen with the further adoption of AutoML.
What Does a Data Scientist Do?
This can have a decent amount of variation by company and domain, but generally: Data Scientists work with Business leaders to experiment and build machine learning models to provide statistical insight and guide high-value business decisions. This often means the role is a highly technical consultant of sorts, internal and/or external.
The entire lifecycle of these projects starts with Data Engineers curating and validating data from a myriad of systems into a suitable format in databases, data lakes, data warehouses, etc. Then as a business need comes up, the Data Scientist is responsible for understanding the problem at hand and what data can be a solution. This requires a decent amount of back and forth with the Data Engineers and Business leaders to find the right sources to pull data from, the quality limitations, and more.
Then the Data Scientists typically build a Proof of Concept model that is more focused on experimentation than scalability. This PoC stage is highly iterative, messy, and exploratory. This stage involves closer collaboration with Data Analysts. The outputs of this stage results in identifying initial strong features, data dependencies, models that work, optimal hyperparameters, limitations of the model/project, and more. The Data Scientist should have a myriad of statistical and algorithmic techniques in their repertoire to tackle the problem at hand. Once we’ve reached a decent level of confidence with the PoC, we’ll refactor the code written so far to optimize for performance so we can have the model live in production.
The Deployment stage involves a partnership with Machine Learning Engineers to help productionize the model and set up adequate model monitoring. The post-deployment work of the project is usually a collaboration between the Data Scientist and the Machine Learning Engineer. Finally, the Data Scientists will deliver presentations that concisely and clearly explain the model, the model results, and how it relates to the business.
That was an incredibly reductionist view of each function which have their own depths and challenges, but operating and owning this entire lifecycle is applied machine learning. Additionally, data projects are usually not linear — they’re iterative. Each stage something usually gets discerned that requires revisiting a previous stage so having all roles involved from the start helps a ton. Lastly, depending on the size and resources available to the organization you can easily have one person playing multiple roles. The most common combination of roles I’ve seen are
- Data Scientist / Machine Learning Engineer: Usually better at performance by creating scalable ML systems that work in domains far past the Jupyter notebook. Essentially what companies mean when they ask for a “Data Scientist”.
- Data Scientist / Data Analyst: Usually better at speed and experimentation. Usually ends up in Lead Analyst or Product DS functions.
- Data Scientist / Data Analyst / Machine Learning Engineer: Typically found in Seniors, Leads, and Principals. Masters of multiple trades.
What Does Automated Machine Learning (AutoML) Do?
AutoML automates the entire machine learning workflow.
It is preferred to be done inside of cloud infrastructures like Google Cloud Platform or Azure Machine Learning or Amazon SageMaker. AutoML works to replace all the manual parts of tuning and model experimentation that today’s Data Scientists do by searching to find optimal hyperparameters and models for the modeling task. It handles the iterative piece as well, as its main function is to optimize evaluation metrics so they will keep iterating until the best results are achieved (or termination criteria is reached).
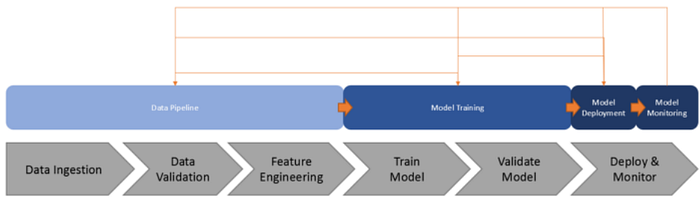
Once trained, it can easily be deployed into a Production instance on the cloud as well where model monitoring checks are set up to review such as Precision-Recall curves, Feature Importances, and more.
The underlying algorithms that AutoML learns are primarily what is already learned by Data Scientists/MLEs, but there usually is little transparency of how these Cloud offerings really perform AutoML. With that being said, you likely will see state-of-the-art models and ensemble models being heavily used here and often times with comparable performance to hand-crafted models.
The incorporation of Data Visualization and Feature Engineering with AutoML is massively useful as well. The systems can identify critical feature crosses, appropriate transformations, and key visualizations along the way.
Finally, these cloud platforms also have specific Deep Learning products with AutoML for use cases such as Vision (ex. Object Detection), NLP (ex. OCR), Time Series (ex. Forecasting), and more.
Who Does AutoML Really Help?
It’s really easy to read the above and say “well the Data Scientist is clearly useless then”. I’d argue the exact opposite. The low-code/no-code movement has been truly wonderful to witness, especially as cloud platforms are getting widely adopted. Highly technical work is becoming drag-and-drop and easier barriers of entry for beginners. In fact, it’s getting so easy that people feel just anyone can do this work with little discussion about the quality and the level of understanding of the work done. The downside of low-code/no-code tools is that it makes it easier to get stuck in the “overconfident, under competent” stage in the Dunning-Kruger Effect.
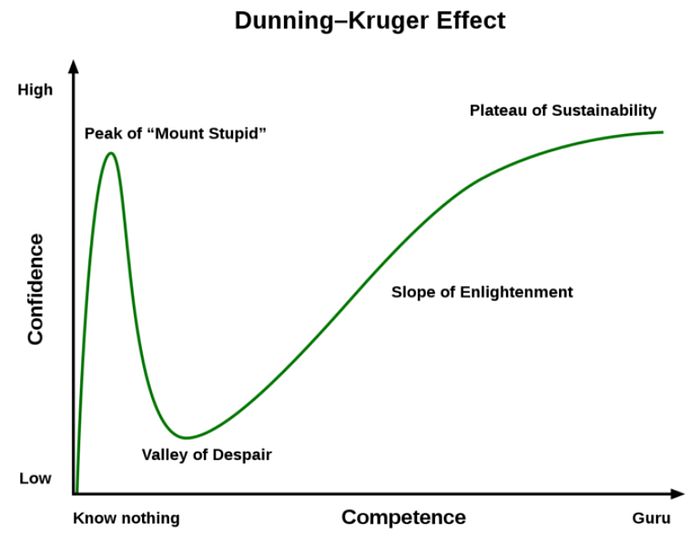
When we heavily abstract highly technical and complicated work, we lower the barrier for entry but also make it easier to people to get stuck at a beginner level. When you can run AutoML with unlimited cloud compute, why ever learn which models are best for the task at hand, why certain models will fail your business use case, why evaluation metrics need to be prioritized based on your problem, and more. The answers to these questions start to shine a light on the true winners of AutoML, but let me draw an analogous comparison first.
Tableau is one of the most popular Data Analysis products today. I started my career in it, have gotten a certification, and am a huge fan of the tool. It was an amazing product to start with because it made what was previously very technical and time-consuming into a simple drag and drop. I could easily make bar charts, pie charts, intricate dashboards, pseudo web pages, and more. As a beginner, this incredibly empowered me and I’m grateful for that. But if I’m being honest, so many of my initial dashboards really sucked. They didn’t spur action, insightful thought, and were more “fun to look at” rather than stories that have a call to action. Even so, it was easy for me to claim expertise because I could ride the tool’s relative ease of use. As I progressed in my career, and in my Masters program, I dived deeper to learn about color theory, limits of vision, purposeful design, and how to build data visualizations with code. This deeper understanding helped me get past that beginner trough, but it could have been very easy for me to keep going guising as an expert. And even now, I have seen a plethora of Tableau dashboards that people feel are effective because they “have an eye for design” when they aren’t effective at all.
Tableau has made it easy for anyone to be a Data Analyst and it has just proved that most people are not good at it. This isn’t meant to be an offense; it’s meant to be a realization that good and quality data analysis is not something that can be reduced to a drag-and-drop tool. It’s deep expertise that takes time and effort to learn to do right, far beyond being able to create bar charts in one click.
AutoML helps Data Scientists more than anyone. Whenever I hear that you can have MBAs and other untrained ML professionals easily do this work, I think it’s comical. The abstraction of the technical complexities makes it easy for newcomers, but the primary audience is always the experts. AutoML automates the most tedious part of the craft, but the work is vastly broader and deeper than just optimizing an ensemble model for accuracy.
Looking Toward a Collaborative Future
Any highly proficient Data Scientist I know is not at all concerned by AutoML; in fact, they’re excited about it. This is because they can’t wait for the most tedious and iterative part of their PoC work to get automated and because they know their true value does not lie in doing this tedious work. AutoML cannot handle the interpretation of models (no, printing evaluation metrics is not interpretation) to business leaders with recommendations of what actions to take, understanding what new features not present in the dataset could be significant and how to get them, how to integrate them into a larger system of models or software built across an enterprise, and more.
I’m sure there are instances where untrained ML professionals have used AutoML, put it in production, and it’s yielding millions in value for the business. The success of this is not attributed to AutoML, it’s attributed to your company’s data culture and infrastructure. The number of stories I’ve read that talk about how Google’s “killing the Data Scientist” with AutoML with little acknowledgment that they are using it at Google. In most companies, you likely will need a centralized governing body that can monitor what models are getting created, why, and how they’re performing if you’re planning to jump on the “citizen data scientist” train.
With that being said, AutoML will kill a certain type of function and that is the “pseudo Data Scientists”. These are Data Scientists or MLEs who are really stuck in that “overconfident, under competent” stage and refuse to learn, grow, and evolve past it. AutoML will make their value proposition significantly decrease and force them into Analyst or MLE functions. Citizen Data Scientists is a juxtaposition but can be okay as long as expectations are managed; you wouldn’t expect quality results from Citizen Doctors or Citizen Lawyers and you shouldn’t here either.
Although I think a lot of those articles are a bit sensationalist, I do believe redefining of roles & responsibilities will come especially due to these tools popping up. I’m not claiming the Data Scientist or MLE role will be completely untouched, but more that their expertise will be needed far more and valued far greater than we do today. Tools like AutoML becoming popularized is a sign that this skill is unanimously needed in spades, and people who can operate it at a high level within their skillset will win the next decade of applied machine learning.
Read more data science articles on OpenDataScience.com, including tutorials and guides from beginner to advanced levels! Subscribe to our weekly newsletter here and receive the latest news every Thursday. You can also get data science training on-demand wherever you are with our Ai+ Training platform. Subscribe to our fast-growing Medium Publication too, the ODSC Journal, and inquire about becoming a writer.
