Build NLP Apps with Transformers and Large Scale Language Models

Transformers have taken the AI research and product community by storm. We have seen them advancing multiple fields in AI such as natural language processing (NLP), computer vision, and robotics. In this blog, I will share some background in conversational AI, NLP, and transformers-based large-scale language models such as BERT and GPT-3 followed by some examples around popular applications and how to build NLP apps.

Natural Language Processing and Conversational AI
Conversational AI involves technologies that make machines interact with humans (or other machines) in a natural and meaningful way. Interaction can involve a specific goal (e.g. “search movie for a weekend”) or non-goal oriented (e.g. social conversations) and can be based on speech, text, and sign language. Building NLP apps and conversational AI systems can involve several tasks such as speech processing, language understanding, dialog management, and language generation. Therefore, it leverages several technologies such as NLP, audio processing, and machine learning.

Conversational AI Leveraging NLP, ML — Created by Infopulse Shah (Medium, 2019)
Evolution of Conversational AI
Conversational AI has been transforming various industries such as automation, contact centers, and virtual assistants. They have undergone several phases of research and development. Prior to the 1990s, most systems were purely based on rules. Then came machine learning-based systems, however, it was still hard to do application-specific featurization of data, and managing multiple domains and scenarios. Post-2013, transfer learning, and deep learning-based systems further enhanced the performance substantially by scaling the system to millions of users across a variety of applications. To address these challenges, “Word-Embedding” based models were built in NLP, and “Skills-based” and “Domain-Intent-Slot” based systems were proposed in Conversational AI. Despite significant progress in the past decade, most systems rely on large amounts of data annotation for language understanding, configurations for dialog management, and templates for language generation. Within the last two years, transformers-based models have been used to depict the power of unsupervised learning and generative systems across all aspects of conversational AI: speech recognition, language understanding, dialog management, and language generation, and to build NLP apps.

Conversational AI Architecture — Created by Nisar Shah (Medium, 2018)
Language Models (LMs) and Transformers based Pre-trained Large Scale LMs
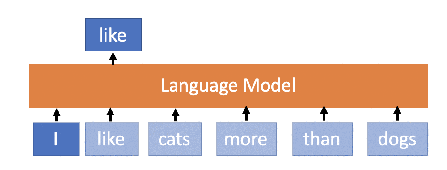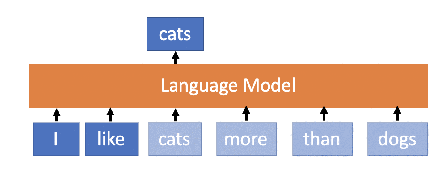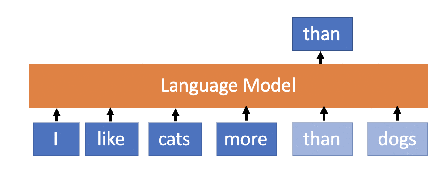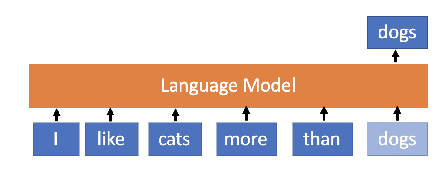
Language Model is a probability distribution over sequences of words. In simple words, LMs learn the sequence of words and their representation. Since we communicate through words, LMs learn the distribution of words for a given language or set of languages or for a given context. That is a good LM for a given language can be seen as the representation of the language itself. Since LMs are trained in a self-supervised manner, i.e. just observing and learning the sequence of words without knowing what words mean, they might know the meaning of the words. What they actually learn is the placement of words given some context.

https://miro.medium.com/max/447/1*bknGoZUriWYabncNGhUU5Q.gif
Language Model Illustration — Source Chauhan Jainish (Medium, 2019)
LMs are of great importance for Conversational AI tasks and to build NLP apps. Once we build or train LMs, they can be used for a variety of applications by simply fine-tuning or updating it to a given task or data. Large Scale Pre-trained LMs such as BERT and GPT-3 are based on the same concept and therefore building them requires training on massive amounts of data (billions of sentences) with hundreds of millions (BERT), hundreds of billions (GPT-3), and trillions of parameters (Switch Transformers). These models are so big that they nearly memorize every single sentence and corresponding context and therefore are great at generating text. Some of the applications which involve sequence generation such as Music Generation, Story Generation, and Response Generation in Conversational AI systems have seen a dramatic improvement with these LMs.

Pre-trained Large Scale Language Model Size — Source Search Engine Watch
How to use Pre-trained Language Models in NLP and Conversational AI Applications?
Organizations like Hugging Face and Google Colab through their open-source contributions have made it really easy for developers and researchers to leverage Pre-trained Large Scale LMs with just a few lines of code to build NLP apps. The open-source nature of such projects has dramatically minimized the pace of research and development. Along with optimizing and scaling, trying new ideas is becoming really easy. A developer just needs to identify the task they are interested in (e.g. text classification, question answering, entity recognition, etc.) and collect corresponding data. For each NLP and Conversational AI task, a catalog of several pre-trained models exist across a variety of languages, which can be used and further fine-tuned by a developer/user on their own task.

Catalog of Pre-trained Large Scale Language Models and Datasets — Source Hugging Face
Examples
As mentioned above, Conversational AI and NLP involve a variety of tasks such as Text-Classification, Summarization, Text Generation, Translation and Question-Answering, and to build NLP apps. Any of these tasks can be easily invoked with Hugging Face transformers. To demonstrate this, let’s install “Huggingface Transformers and Datasets”:
pip install transformers
pip install datasetsOnce installed, let’s follow these steps:
1. Identify the task: You can start with any of the tasks listed above. Hugging Face supports a variety of models. Let’s choose the text classification task using AutoModelForSequenceClassification. Let’s also choose the “BERT” model.
2. Identify the model, config, and tokenizers: You can also choose a model using AutoClasses. You may also optionally use the config related to your task. Hugging Face has a catalog of config which you can start with:
from transformers import AutoConfig, AutoTokenizer,
AutoModelForSequenceClassification
config = AutoConfig.from_pretrained('bert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_config(config)3. Get and prepare your data: “Datasets” python library from Hugging Face has thousands of datasets. You can start from that or use your own using this library. Let’s take an example of IMDb sentiment classification dataset. We can either load the data directly using the “Datasets” library or build from scratch. Let’s first download it and then prepare it using these two approaches:
#Using datasets library:
from datasets import load_dataset
dataset = load_dataset("imdb")#Or load data from scratch
wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
tar -xf aclImdb_v1.tar.gzfrom pathlib import Pathdef read_imdb_split(split_dir):
split_dir = Path(split_dir)
texts = []
labels = []
for label_dir in ["pos", "neg"]:
for text_file in (split_dir/label_dir).iterdir():
texts.append(text_file.read_text())
labels.append(0 if label_dir is "neg" else 1)
return texts, labels
# This could be a large dataset and your machine/gpu can go out of memory. You can sample from this dataset and experiment with a smaller slice.
train_texts, train_labels = read_imdb_split('aclImdb/train')
test_texts, test_labels = read_imdb_split('aclImdb/test')# Further splitting train into train and validation sets for model to train in a better way
from sklearn.model_selection import train_test_split
train_texts, val_texts, train_labels, val_labels = train_test_split(train_texts, train_labels, test_size=.1)
4. Obtain encodings using Tokenizer and Tensor: Machines do not understand text and neural networks such as Transformers take numerical input. Therefore, text data needs to be first tokenized in smaller units and then encoded into rich numerical embeddings. Hence, we transform text data using the model’s tokenizer and then transform into tensors to be consumed in models:
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)import torchclass IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item def __len__(self):
return len(self.labels)train_dataset = IMDbDataset(train_encodings, train_labels)
val_dataset = IMDbDataset(val_encodings, val_labels)
test_dataset = IMDbDataset(test_encodings, test_labels)
5. Train the model using the Trainer class: Now we are all set. We can simply train and evaluate the model using Hugging Face Trainer Class.
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)trainer.train()
6. Evaluate model on evaluate and test datasets:
eval_results = trainer.evaluate()
print("Evaluation Results: ", eval_results)test_results = trainer.evaluate(eval_dataset=test_dataset)
print("Test Results: ", test_results)
Similar to the text classification example above, you can use other tasks as well. The code is available at the following github repository.
Democratizing Conversational AI using Transformers and Pre-Trained Large Scale LMs
The true democratization of Conversational AI would involve providing access to all application users with models that have the capability to “Self Train” and “Self Manage”, by discovering patterns from data automatically. Then it’s not about data pipelines, and ML toolkits. The AI models deal with those themselves. It just makes Deep Learning and AI so much more accessible. Got It AI, which is one of the leading Conversational AI R&D firms, is making this vision of Democratization into reality by leveraging Transformers and Pre-trained Large Scale LMs. It has built Conversational AI models and products which “Self Train” and “Self Manage” and letting users and customers simply monitor and validate via “No Code AI”.
Editor’s note: Chandra is a speaker for ODSC East 2021. Check out his talk, “Advances in Conversational AI and NLP through Large Scale Language Models such as GPT-3,” there!
Author/ODSC East 2021 Speaker:

Chandra Khatri: Chief Scientist and Head of AI Research, Got It AI
https://sites.google.com/view/chandra-khatri/
https://www.linkedin.com/in/ckhatri/
Bio:
Chandra Khatri is the Chief Scientist and Head of AI Research and Got It AI. He is also one of the leading experts in the field of Conversational AI. Prior to Got It AI he was leading Conversational AI and Multimodal efforts at Uber AI. He was the founding Scientist of Amazon Alexa Prize and has served as Chair or organized several AI conferences and workshops. He is best known for leveraging cutting-edge technologies and research for transforming products impacting hundreds of millions of users.

{kind=link}