How Bayesian Machine Learning Works

Bayesian methods assist several machine learning algorithms in extracting crucial information from small data sets and handling missing data. They play an important role in a vast range of areas from game development to drug discovery. Bayesian methods enable the estimation of uncertainty in predictions which proves vital for fields like medicine. The methods help saving time and money by allowing the compression of deep learning models a hundred folds and automatically tuning hyperparameters.
This article is an excerpt from Machine Learning for Algorithmic Trading, Second Edition by Stefan Jansen — a book that illustrates end-to-end machine learning for the trading workflow, from the idea and feature engineering to model optimization, strategy design, and backtesting. In this section, we discuss how Bayesian machine learning works
[Related article: Introduction to Bayesian Deep Learning]
Classical statistics is said to follow the frequentist approach because it interprets probability as the relative frequency of an event over the long run that is, after observing many trials. In the context of probabilities, an event is a combination of one or more elementary outcomes of an experiment, such as any of six equal results in rolls of two dice or an asset price dropping by 10 percent or more on a given day.
Bayesian statistics, in contrast, views probability as a measure of the confidence or belief in the occurrence of an event. The Bayesian perspective, thus, leaves more room for subjective views and differences in opinions than the frequentist interpretation. This difference is most striking for events that do not happen often enough to arrive at an objective measure of long-term frequency.
Put differently, frequentist statistics assumes that data is a random sample from a population and aims to identify the fixed parameters that generated the data. Bayesian statistics, in turn, takes the data as given and considers the parameters to be random variables with a distribution that can be inferred from data. As a result, frequentist approaches require at least as many data points as there are parameters to be estimated. Bayesian approaches, on the other hand, are compatible with smaller datasets, and well suited for online learning from one sample at a time.
The Bayesian view is very useful for many real-world events that are rare or unique, at least in important respects. Examples include the outcome of the next election or the question of whether the markets will crash within 3 months. In each case, there is both relevant historical data as well as unique circumstances that unfold as the event approaches and how Bayesian machine learning contributes.
How to update assumptions from empirical evidence
The theorem that Reverend Thomas Bayes came up with, over 250 years ago, uses fundamental probability theory to prescribe how probabilities or beliefs should change as relevant new information arrives. The preceding Keynes quotation captures that spirit. It relies on the conditional and total probability and the chain rule; see Bishop (2006) and Gelman et al. (2013) for an introduction and more.
The probabilistic belief concerns a single parameter or a vector of parameters θ (also: hypotheses). Each parameter can be discrete or continuous. θ could be a one-dimensional statistic like the (discrete) mode of a categorical variable or a (continuous) mean, or a higher dimensional set of values like a covariance matrix or the weights of a deep neural network.
A key difference to frequentist statistics is that Bayesian assumptions are expressed as probability distributions rather than parameter values. Consequently, while frequentist inference focuses on point estimates, Bayesian inference yields probability distributions.
Bayes’ theorem updates the beliefs about the parameters of interest by computing the posterior probability distribution from the following inputs, as shown in Figure 1:
- The prior distribution indicates how likely we consider each possible hypothesis.
- The likelihood function outputs the probability of observing a dataset when given certain values for the parameters θ, that is, for a specific hypothesis.
- The evidence measures how likely the observed data is, given all possible hypotheses. Hence, it is the same for all parameter values and serves to normalize the numerator.

Figure 1: How evidence updates the prior to the posterior probability distribution
The posterior is the product of prior and likelihood, divided by the evidence. Thus, it reflects the probability distribution of the hypothesis, updated by taking into account both prior assumptions and the data. Viewed differently, the posterior probability results from applying the chain rule, which, in turn, factorizes the joint distribution of data and parameters.
With higher-dimensional, continuous variables, the formulation becomes more complex and involves (multiple) integrals. Also, an alternative formulation uses odds to express the posterior odds as the product of the prior odds, times the likelihood ratio (see Gelman et al. 2013).
Exact inference — maximum a posteriori estimation
Practical applications of Bayes’ rule to exactly compute posterior probabilities are quite limited. This is because the computation of the evidence term in the denominator is quite challenging. The evidence reflects the probability of the observed data over all possible parameter values. It is also called the marginal likelihood because it requires “marginalizing out” the parameters’ distribution by adding or integrating over their distribution. This is generally only possible in simple cases with a small number of discrete parameters that assume very few values.
Maximum a posteriori probability (MAP) estimation leverages the fact that the evidence is a constant factor that scales the posterior to meet the requirements for a probability distribution. Since the evidence does not depend on θ, the posterior distribution is proportional to the product of the likelihood and the prior. Hence, MAP estimation chooses the value of θ that maximizes the posterior given the observed data and the prior belief, that is, the mode of the posterior.
The MAP approach contrasts with the Maximum Likelihood Estimation (MLE) of parameters that define a probability distribution. MLE picks the parameter value θ that maximizes the likelihood function for the observed training data.
A look at the definitions highlights that MAP differs from MLE by including the prior distribution. In other words, unless the prior is a constant, the MAP estimate will differ from its MLE counterpart:
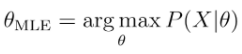
The MLE solution tends to reflect the frequentist notion that probability estimates should reflect observed ratios. On the other hand, the impact of the prior on the MAP estimate often corresponds to adding data that reflects the prior assumptions to the MLE. For example, a strong prior that a coin is biased can be incorporated in the MLE context by adding skewed trial data.
Prior distributions are a critical ingredient to Bayesian models. We will now introduce some convenient choices that facilitate analytical inference.
How to select priors
The prior should reflect knowledge about the distribution of the parameters because it influences the MAP estimate. If a prior is not known with certainty, we need to make a choice, often from several reasonable options. In general, it is good practice to justify the prior and check for robustness by testing whether alternatives lead to the same conclusion.
There are several types of priors: regarding how Bayesian machine learning works
- Objective priors maximize the impact of the data on the posterior. If the parameter distribution is unknown, we can select an uninformative prior like a uniform distribution, also called a flat prior, over a relevant range of parameter values.
- In contrast, subjective priors aim to incorporate information external to the model into the estimate. In the Black-Litterman context, the investor’s belief about an asset’s future return would be an example of a subjective prior.
- An empirical prior combines Bayesian and frequentist methods and uses historical data to eliminate subjectivity, for example, by estimating various moments to fit a standard distribution. Using some historical average of daily returns rather than a belief about future returns would be an example of a simple empirical prior.
In the context of a machine learning model, the prior can be viewed as a regularizer because it limits the values that the posterior can assume. Parameters that have zero prior probability, for instance, are not part of the posterior distribution. Generally, more good data allows for stronger conclusions and reduces the influence of the prior.
How to keep inference simple — conjugate priors
A prior distribution is conjugate with respect to the likelihood when the resulting posterior is of the same class or family of distributions as the prior, except for different parameters. For example, when both the prior and the likelihood are normally distributed, then the posterior is also normally distributed.
The conjugacy of prior and likelihood implies a closed-form solution for the posterior that facilitates the update process and avoids the need to use numerical methods to approximate the posterior. Moreover, the resulting posterior can be used as the prior for the next update step.
Let’s illustrate this process using a binary classification example for stock price movements

Dynamic probability estimates of asset price moves
When the data consists of binary Bernoulli random variables with a certain success probability for a positive outcome, the number of successes in repeated trials follows a binomial distribution. The conjugate prior is the beta distribution with support over the interval [0, 1] and two shape parameters to model arbitrary prior distributions over the success probability. Hence, the posterior distribution is also a beta distribution that we can derive by directly updating the parameters.
We will collect samples of different sizes of binarized daily S&P 500 returns, where the positive outcome is a price increase. Starting from an uninformative prior that allocates equal probability to each possible success probability in the interval [0, 1], we compute the posterior for different evidence samples.
The following code sample shows that the update consists of simply adding the observed numbers of success and failure to the parameters of the prior distribution to obtain the posterior:
n_days = [0, 1, 3, 5, 10, 25, 50, 100, 500] outcomes = sp500_binary.sample(n_days[-1]) p = np.linspace(0, 1, 100) # uniform (uninformative) prior a = b = 1 for i, days in enumerate(n_days): up = outcomes.iloc[:days].sum() down = days - up update = stats.beta.pdf(p, a + up , b + down)
The resulting posterior distributions have been plotted in the following image. They illustrate the evolution from a uniform prior that views all success probabilities as equally likely to an increasingly peaked distribution.
After 500 samples, the probability is concentrated near the actual probability of a positive move at 54.7 percent from 2010 to 2017. It also shows the small differences between MLE and MAP estimates, where the latter tends to be pulled slightly toward the expected value of the uniform prior:
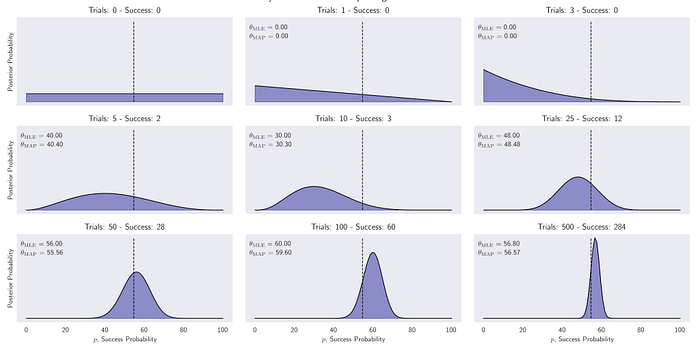
Figure 2: Posterior distributions of the probability that the S&P 500 goes up the next day after up to 500 updates
In practice, the use of conjugate priors is limited to low-dimensional cases. In addition, the simplified MAP approach avoids computing the evidence term but has a key shortcoming, even when it is available: it does not return a distribution so that we can derive a measure of uncertainty or use it as a prior. Hence, we need to resort to an approximate rather than exact inference using numerical methods and stochastic simulations.
Summary on How Bayesian Machine Learning works
In this article, we learnt the Bayes’ theorem which crystallizes the concept of updating beliefs by combining prior assumptions with new empirical evidence, and compare the resulting parameter estimates with their frequentist counterparts. We also explored conjugate priors, which produce insights into the posterior distribution of latent. Machine Learning for Algorithmic Trading, Second Edition encompasses methods in detail and more about how Bayesian machine learning can be leveraged to potentially broader extent by designing and back-testing automated trading strategies for real-world markets.
[Related article: Hierarchical Bayesian Models in R]
About the Author
Stefan Jansen is the founder and CEO of Applied AI. He advises Fortune 500 companies, investment firms, and startups across industries on data & AI strategy, building data science teams, and developing end-to-end machine learning solutions for a broad range of business problems.
Before his current venture, he was a partner and managing director at an international investment firm, where he built the predictive analytics and investment research practice. He was also a senior executive at a global fintech company with operations in 15 markets, advised Central Banks in emerging markets, and consulted for the World Bank.
He holds master’s degrees in Computer Science from Georgia Tech and in Economics from Harvard and Free University Berlin, and a CFA Charter. He has worked in six languages across Europe, Asia, and the Americas and taught data science at Data camp and General Assembly.
Editor’s note: Interested in learning how Bayesian machine learning and deep learning work? Check out these upcoming talks at ODSC West 2020 this October:
– “Bayesian Workflow as Demonstrated with a Coronavirus Example” — Andrew Gelman, PhD, Director of Applied Statistics Center | Columbia University
– “The Bayesians are Coming! The Bayesians are Coming, to Time Series” — Aric LaBarr, PhD, Associate Professor of Analytics | Institute for Advanced Analytics at NC State University
– Bayesian Statistics Made Simple” — Allen Downey, PhD, Computer Science Professor | Olin College and Author of Think Python, Think Bayes, Think Stats
