Just Enough Theoretical Underpinnings for NLP

“How do you say good morning in Spanish?” — This is an early research example in the field of Natural Language Processing (NLP) dated back to the 1950s. Using statistical techniques to analyze the human language then became popular in the 1990s; fast forward to two decades later in the 2010s, research efforts have evolved to focus on using deep neural networks for NLP. We hear about more and more new models with millions and billions of parameters, e.g. BERT, XLNet, ALBERT, etc., but are they really entirely different from one another? How about methods like tf-idf, word2vec? Are they still relevant and useful? How do we keep up with the constant evolution and innovation in the NLP field? How do we start understanding the model details behind the scene, rather than just using these models?
Start with the common and basic theoretical foundation.

Deep learning or not, probabilistic language modeling is a common thread across all NLP tasks.

Count-based Approaches
In the non-deep learning realm, probabilistic language models (LMs) leverage count-based approaches, which represent words in terms of their frequencies. As an example, let’s now try to set up n-grams and bag-of-words (BOW) in the framework of a Naive Bayes classification model.

Naive Bayes treats the entire input text as a bag of words and models the probability of text based on unigrams.

On the other hand, positive pointwise mutual information (PPMI) frames the probabilistic LM problem by asking “do words w1 and w2 co-occur more than if they were independent?” While Term Frequency-Inverse Document Frequency (TF-IDF) calculates a term’s importance based on the term frequency relative to other terms in other documents, there have also been attempts to estimate the probability of any given document d containing a term t.
Prediction-based Approaches
Count-based methods result in high sparsity in word representation vectors and typically do not generalize well — what if there are new words not present in your training vocabulary? We encounter very different vocabulary when reading The Lord of the Rings vs. reading The New York Times vs. Twitter. The idea that we could use the text at hand as implicitly supervised training data was a paradigm shift in framing NLP tasks. NLP approaches started to pivot away from count-based to prediction-based.
Word2Vec is a single-layered neural network that hinges upon training binary prediction tasks based on a window of nearby words; for instance, is the word “hobbit” likely to show up near “ring”? Then, we use the model weights as the word embeddings, which are vector representations of words. Word2Vec is quick to train but does not take global context into account.
On the other hand, since words that occur together may encode some form of meaning, Global Vectors for Word Representation (GloVe) generates embeddings by aggregating a global matrix of word co-occurrence. For example, one would expect to see the words “ice” and “solid” more frequently together than “ice” and “gas”.

Image sourced from nlp.stanford.edu
One fundamental limitation that both Word2Vec and GloVe share is that they do not know how to deal with out-of-vocabulary (OOV) words. This is where fastText comes in. fastText looks at substrings of words; therefore, each word is a sum of its N-grams and each N-gram ranges from 3 to 6 characters.

Image sourced from the fastText paper
Contextual Approaches (Deep Learning)
None of the methods discussed above is able to capture contextual information well.

Hence, we turn to neural network architecture to process long sequences. Here, probabilistic LMs manifest in that a neural network predicts the probability distribution of every word, given words that the model has seen so far. First, let’s discuss recurrent neural networks (RNNs) briefly. RNNs are feedback loops that cycle over the sequences. The most popular RNN variant in NLP is Long Short-Term Memory (LSTM). While vanilla RNNs have bottleneck difficulties accessing information from many steps back, LSTMs have a separate memory cell with built-in forget gates. LSTMs forget unimportant information.
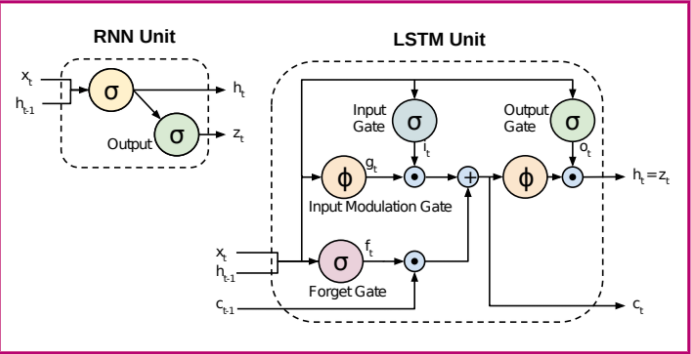
Image sourced from Raseem et al. 2017
A notable model architecture that uses LSTMs is Embeddings from Language Models (ELMo). ELMo is bidirectional and concatenates the input text from left to right, and right to left, mirroring a human reader’s experience. However, the concatenation means that the training process could not take advantage of both left and right contexts simultaneously nor resolve the bottleneck problem completely.
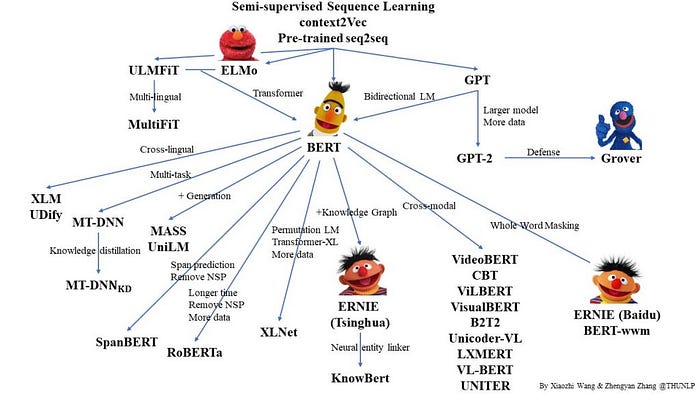
This leads to our most popular architecture: Transformers. Transformers leverage attention mechanisms; as the name implies, attention attends to its inputs, which means it pays most attention to the most important words. Furthermore, transformers allow simultaneous processing of text by additionally encoding the word positions. Therefore, transformers have a faster model training process and thanks to positional word encodings, we do not have to worry about the word order being jumbled up.
BERT (Bidirectional Encoder Representation from Transformers), published in 2019, is actually a variant of the original transformer architecture implemented in 2017. Unlike the original encoder-decoder transformer architecture meant for sequence generation tasks, i.e. machine translation, BERT does not have a decoder component. An architectural difference as such indicates that BERT is not trained for sequence generation tasks.
Today, we hear about a variety of other transformer architectures, namely RoBerta, XLNet, ALBERT, and so on. These models are built upon BERT and share a lot of commonalities in the architecture, despite improving upon the training processes. In order to keep up with the evolution of the NLP landscape, it is necessary to understand only the foundation of attention and the BERT architecture.
Summary
In this article, you learned that probabilistic language modeling is at the core of NLP tasks. You also learned the motivation of moving from count-based to prediction-based to deep contextual models, and the high-level comparisons among these models. You now have just enough theoretical background to get started in NLP!
Read more data science articles on OpenDataScience.com, including tutorials and guides from beginner to advanced levels! Subscribe to our weekly newsletter here and receive the latest news every Thursday. You can also get data science training on-demand wherever you are with our Ai+ Training platform. Subscribe to our fast-growing Medium Publication too, the ODSC Journal, and inquire about becoming a writer.