Training a Medication Named-Entity Recognition Model From Scratch with spaCy
Editor’s note: Ben is a speaker for ODSC East 2022. Be sure to check out his talk, “Neural Named-Entity Recognition pipelines with spaCy,” there!
The uptake of Electronic Health Record (EHR) systems grew five-fold between 2008 and 2013 and has only been increasing since. These record systems often contain large sections of unstructured text where doctors will write observations and details about a patient visit. These clinical notes have been used for identifying adverse drug events (https://pubmed.ncbi.nlm.nih.gov/33215076/), de-identification (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7153082/) and identifying cancer stage (https://pubmed.ncbi.nlm.nih.gov/26306621/).
All of the above examples use Natural Language Processing (NLP) pipelines and focus on the identification of real-world entities (e.g. medication name), a task commonly referred to as Named-Entity Recognition (NER). Performance on these tasks is highly dependent on context. One named-entity recognition model for clinical de-identification achieved nearly perfect performance on its test set, but barely passed an F1 0.6 when tested on a new dataset (https://arxiv.org/pdf/2010.05143v1.pdf). For these models to be usable, they need to be fit to the context to which they will be deployed.

Enter spaCy: A versatile Python library that’s designed to manage NLP pipelines from start to finish. That means data ingestion, tokenization, tagging, and representation. With the recent v3.0 release, the team added a streamlined “project” workflow that neatly packages these components together. In my upcoming tutorial at ODSC East, I’ll be going through how to customize these pipelines for medication identification in two contexts. In one, we’ll use a social media dataset (https://github.com/explosion/projects/tree/v3/tutorials/ner_drugs), but the one I want to focus on here is using actual clinical notes.
The dataset comes from the 2018 National NLP Clinical Challenges (n2c2) (https://portal.dbmi.hms.harvard.edu/) and contains clinical notes with medications and their attributes (e.g. dosage) labeled by expert annotators. My goal is to develop an NER pipeline that can identify a subset of these entities (i.e. medication name, dosage, form, and frequency). I can’t share these data here, but you can register for a free account to access them on the website linked above.
A quick overview of how SpaCy works (given in more detail here: https://spacy.io/api): Text is passed through a “language model”, which is essentially the entire NLP pipeline in a single object. That means that the output of the model contains the tokenization and any tagging provided by components of the model (e.g. named-entities). Some of these components can be trained, which is what we’ll be doing here.
The new “project” structure in v3.0 goes one level up from these language models, enabling you to detail data assets and other parameters for training, evaluation, and even serving and visualization. You can see a complete pipeline example here https://github.com/explosion/projects/tree/v3/tutorials/ner_drugs.
You’ll see in that example that there is a “project.yml” file. This gives you an overview of the whole pipeline. The first step in that project file is preprocessing. For the n2c2 context, I wrote a custom preprocessing script (https://github.com/bpben/spacy_ner_tutorial/blob/master/i2b2/scripts/preprocess_i2b2.py). At a high level, the goal is to create a set of Doc (https://spacy.io/api/doc) objects that can then be compressed into spaCy’s special DocBin (https://spacy.io/api/docbin) format for training and evaluation. The n2c2 format for this challenge looks like this (not real data):
<file_id>.txt
Patient had a headache, so I prescribed one advil<file_id>.ann
T1 Reason 15 23 headache
R1 Reason-Drug Arg1:T1 Arg2:T3
T3 Drug 45 50 advil
T5 Dosage 40 43 one
Each note has a set of annotations. Each text (T) annotation has four parts: Id, label, character start/end, and text. You’ll notice there are also relation (R) annotations, but we will not be using those here. The “T” annotations will be added to the set of entities for each Doc object (doc.ents). To do that we need to convert them to Span objects, which line them up with spaCy’s tokenization of the document. Once they’re synced up, we can add the Doc with its entities to the DocBin and output for the training and evaluation steps.
The next step in the project is training. The spaCy example above uses spaCy’s default neural named-entity recognition model, which is explained in detail elsewhere (https://spacy.io/universe/project/video-spacys-ner-model). You can see the details of this training pipeline in the config.cfg file in the above example. The “components” section contains the different pieces. Here is a rough diagram of how the sections map onto the architecture below:
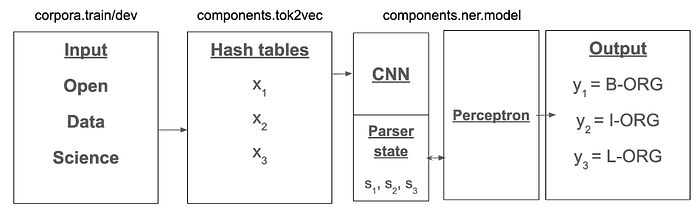
With minimal modification, you can run this same training configuration on the n2c2 data. You can see the config I use here: (https://github.com/bpben/spacy_ner_tutorial/blob/master/i2b2/configs/config.cfg).
Once this is run, you will get the model’s performance on the development set. The performance I got on each entity type is listed below:
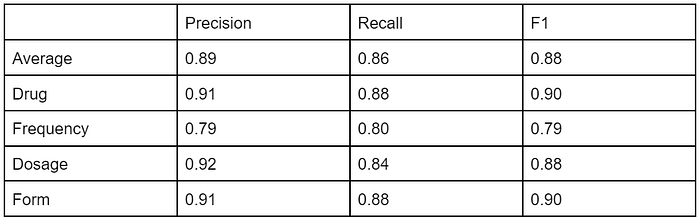
You’ll see that out of the box, the performance of this model is reasonable. Compared to the results of the top-performing teams on the challenge (>=0.90 F1), this doesn’t quite stack up (https://academic.oup.com/jamia/article/27/1/3/5581277). But remember, this is a first-pass approach. One thing we could do to improve is try a new model like a transformer. SpaCy allows us to swap one in to replace the hash table+CNN approach of the baseline model. You can see the updated configuration here: (https://github.com/bpben/spacy_ner_tutorial/blob/master/i2b2/configs/config_trf.cfg).
Note that now there’s a transformer component, which uses the ClinicalBERT model (https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT), a BERT-based model trained on medical text. Just like the hash table+CNN this component will output token-level encodings, which then get fed into the transition-based parser. Also like the hash table+CNN, the resulting gradients will be passed back to adjust the weights of the transformer.
A warning here — transformer models are typically trained on GPUs, since they tend to be computationally expensive. If you’re planning on trying this out, you might want to consider using Google Collaboratory (https://colab.research.google.com). By using the GPU runtime (free!), you should have no problem training the model.
The result is much improved. You can see that below:
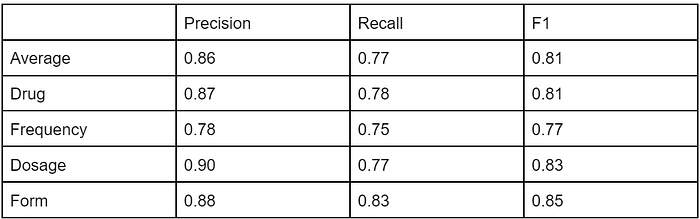
The model hits the low end (0.90 F1) of the top-performers on Drug and Form, which is pretty impressive for being an out-of-the-box solution. For me, that’s what is really exciting here; with limited tweaking, these tools allow you to train a performant neural named-entity recognition model on your local context.
If you’re interested in learning more and diving in a bit deeper, join me and others in April at ODSC East at my session, “Neural Named-Entity Recognition pipelines with spaCy“!
Read more data science articles on OpenDataScience.com, including tutorials and guides from beginner to advanced levels! Subscribe to our weekly newsletter here and receive the latest news every Thursday. You can also get data science training on-demand wherever you are with our Ai+ Training platform. Subscribe to our fast-growing Medium Publication too, the ODSC Journal, and inquire about becoming a writer.
