Using Apache Kafka and Apache Pinot for User-Facing, Real-Time Analytics

Editor’s note: Both Neha Pawar and Karin Wolok are speakers for ODSC East 2022. Be sure to check out their talk, “Using Apache Kafka and Apache Pinot for User-Facing, Real-Time Analytics,” there!
What is user-facing real-time analytics?
When you hear “decision-maker,” it’s natural to think, “C-suite,” or “executive.” But these days, we’re all decision-makers. Restaurant owners, bloggers, big-box shoppers, diners — we all have important decisions to make. Gone are the days when analytics was only something available to execs & analysts in board rooms, or to a handful of data scientists running ad hoc queries with relaxed latency expectations. Businesses are realizing that the end-users of their applications also want access to instant actionable insights and they can build a far more engaging product experience by sharing analytical insights with all end users.

It doesn’t stop at just the accessibility of insights to end-users. The data must be presented at just the right point in time to capture an opportunity for the user. “Yesterday” might be a long time ago for some business. Insights are the most valuable to them if they’re delivered as close to instant as they can possibly be. At the same time, the value increases dramatically over time as it allows for better and richer forecasts.

One of the best adoption stories of user-facing real-time analytics that transformed the end-user product experience, is UberEats Restaurant Manager, an application created by Uber, to provide restaurant owners instant insights about their orders data. On the dashboard, you can see sales metrics, missed orders, inaccurate orders in a real-time fashion, along with other things such as top-selling items, menu feedback, and so on.

Now as you can imagine, to load this dashboard, we need to execute multiple complex OLAP queries, all executing concurrently, multiply this with all restaurant owners across the globe, which leads to a lot of queries per second for the underlying database.
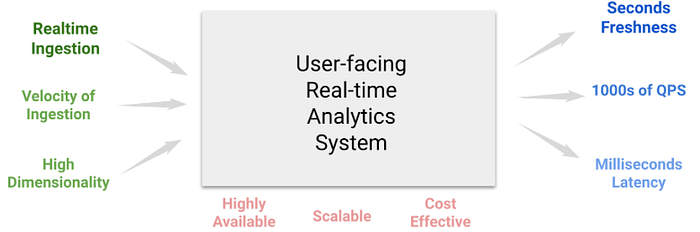
Along with this, the data must be as fresh as possible, and queries must execute in the order of milliseconds so that the users get a good interactive experience
Challenges of user-facing real-time analytics
Providing user-facing, personalized analytics to all end-users in a real-time, scalable and efficient way, is a hard problem. The user is going to expect the freshest data, so, the system needs to ingest real-time data, and make it queryable instantly. The data coming in for such applications arrive at extremely high events/second rate, and tends to be highly dimensional. The results are expected with ultra-low latency, even at extremely high throughput. Plus, as a system, you’d want it to be highly available, reliable, scalable and have a low cost to serve.
Apache Kafka and Apache Pinot
Apache Kafka is the de facto standard for real-time event streaming, and perfectly solves the problem of real-time ingestion for high velocity, volume, and variability of data.
Apache Pinot is a distributed OLAP datastore that can provide ultra-low latency even at high throughput. It can ingest data from batch data sources such as Hadoop, S3, Azure, and streaming sources such as Kafka and Kinesis, making it available for querying in real-time. At the heart of the system is a columnar store along with a variety of smart indexing techniques and pre-aggregation techniques, for low latency.

In our talk at ODSC East 2022, we’ll provide an introduction to both systems and a view of how they are integrated to work together to solve all problems discussed above. We’ll get an in-depth look into the streaming ingestion mechanism from Kafka to Pinot, and how it is designed to be deterministic, scalable, and fault-tolerant. We’ll see how Pinot can ingest unstructured and semi-structured data from Kafka and natively apply transformations, eliminating the need for complex preprocessing jobs and postprocessing query udfs. We’ll discuss the various optimizations in place in Pinot, such as partitioning techniques, indexing, smart query routing, and segment assignment strategies, and how they help with increasing throughput and squeezing out the best possible latency. We’ll go deep into some of the unique indexing strategies in Pinot, from the familiar inverted index, sorted index, all the way to range index, star-tree index, json index, geospatial index, and more. We’ll look at some innovative features in Pinot, such as the ability to upsert events, opening the gates for interesting use-cases in real-time analytics.
All in all, we will explore how Pinot and Kafka are a match made in heaven, for providing blazing-fast user-facing real-time analytics.
Read more data science articles on OpenDataScience.com, including tutorials and guides from beginner to advanced levels! Subscribe to our weekly newsletter here and receive the latest news every Thursday. You can also get data science training on-demand wherever you are with our Ai+ Training platform. Subscribe to our fast-growing Medium Publication too, the ODSC Journal, and inquire about becoming a writer.
